昨晚,大模型圈又热闹了! 字节跳动旗下 Seed 团队,悄悄在深夜甩出了一个重磅炸弹 —— Seed-OSS 系列开源大模型。
不仅规模庞大(360 亿参数),还自带多项黑科技:超长上下文(512K)+ 灵活推理预算 + 强悍的智能体能力。一句话总结:这是目前最值得关注的开源大模型之一。
一口气开源三款模型
这次,Seed 团队一次性放出了 三个版本:
- Seed-OSS-36B-Base(含合成数据)
- Seed-OSS-36B-Base(不含合成数据)
- Seed-OSS-36B-Instruct(指令微调版)
👉 GitHub 项目地址:
https://github.com/ByteDance-Seed/seed-oss
👉 Hugging Face 地址:
https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct
全部以 Apache-2.0 开源许可证发布,也就是说:无论是学术研究还是企业落地,开发者都可以自由使用、修改、再分发。
为什么它很特别?
字节这次开源的 Seed-OSS 系列,有几个“杀手锏”:
- 原生超长上下文(512K tokens) 能一口气读完约 1600 页文档,直接把 OpenAI 最新 GPT-5 的两倍上下文打包送上。 想象一下:长篇论文、合同审阅、复杂推理任务,几乎“无压力”。
- 灵活推理预算 简单说,就是你可以控制模型“思考多久再回答”。
- 任务简单?直接设为 0,让模型立刻出答案。
- 任务复杂?可以拉高到 8K、16K,甚至更长,让模型慢慢推理出更优解。 这种“思考时间可调”的设计,最近在 NVIDIA 等模型中也出现过,但字节这次给足了灵活度。
- 智能体(Agent)能力 在工具调用、任务分解、复杂问题求解上表现突出,明显是在往“AI 助手”方向靠拢。
- 研究友好 Base 模型提供了“含合成数据”和“不含合成数据”两个版本,方便研究者验证合成数据对模型训练的影响。
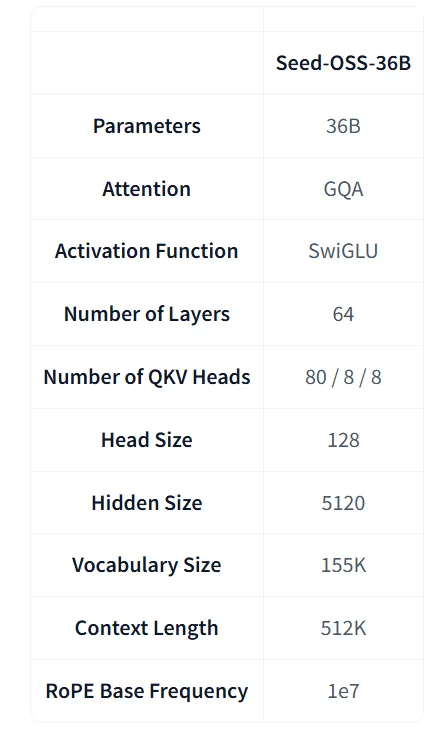
模型架构:硬核但实用
Seed-OSS-36B 的架构结合了多项主流设计:
- 360 亿参数,分布在 64 层网络
- 分组查询注意力(Grouped Query Attention)
- SwiGLU 激活函数、RMSNorm、RoPE 位置编码
- 词表规模 15.5 万
简单来说,既有“大力出奇迹”的算力堆料,也有细节上的工程优化。
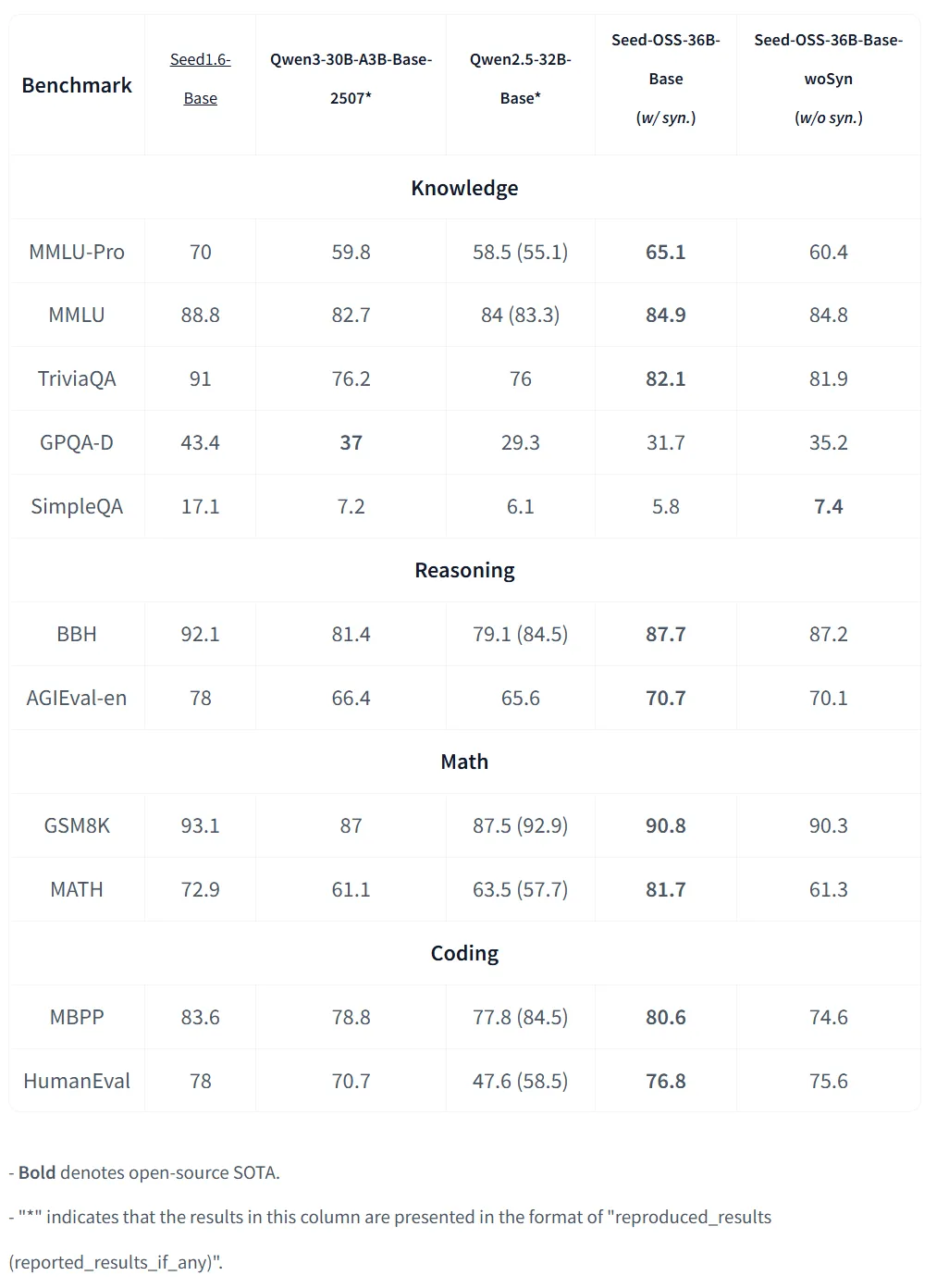
实测成绩:直接冲上开源第一梯队
字节并不是“喊口号”,而是实打实地交出了成绩单:
- 数学与推理: Instruct 版在 AIME24 拿下 91.7%,BeyondAIME 拿下 65 —— 这就是最新的 开源 SOTA!
- 代码能力: 在 LiveCodeBench v6 上拿到 67.4,再度刷新记录。
- 长上下文能力: 在 RULER(128K context)测试中取得 94.6 分,目前开源模型最高。
而 Base 版的 MMLU-Pro(65.1)、MATH(81.7)成绩,也能排进开源大模型的前列。
一句话:不论推理、数学、代码还是长上下文,Seed-OSS-36B 都是天花板级别的存在。
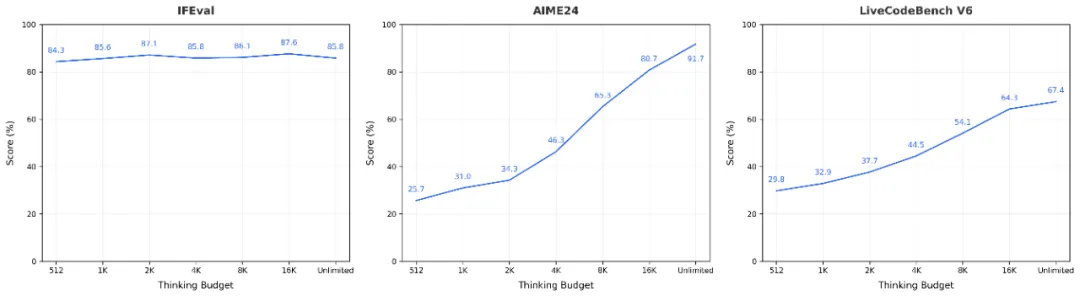
思考预算:决定模型“想多远”
这次最有意思的设计,就是所谓的 推理预算。
📌 举个例子:
- 如果任务是 选择题/简单问答,模型可能“想一想就能答”,推理预算小也能拿高分。
- 如果是 复杂数学题/代码生成,预算越高,模型越容易给出正确解答。
字节推荐的设定是 512 的倍数(512、1K、2K、4K、8K、16K...),因为模型就是在这些区间上被重点训练的。
这相当于给开发者一把“控制模型智商的遥控器”。
总结:字节在开源赛道“卷”出新高度
过去一年,开源大模型百花齐放,但能在 长上下文、推理预算、数学/代码能力 同时亮眼的,寥寥无几。
字节 Seed-OSS 的出现,不仅让 国内开源模型阵营更有竞争力,也让开发者在大模型应用落地时有了更多选择。
未来,它会不会成为开源界的“新标杆”?
拭目以待。

大家好,我是开放猫AI工具库公众号的主理人开放猫,今后我将会在这个公众号分享国内外有趣好用的AI工具,帮助大家通过AI提高学习工作效率!欢迎大家的点赞、关注。
最后也给大家准备了一份近期非常热门资料,包含自媒体应用合集、Coze 搭建手册、高阶视频搭建教学、提示词大全等,也欢迎大家加我微信,免费领取。
另外,知识星球的超强实战资源原价99元,现价29元,欢迎大家扫码咨询!


相关文章

