










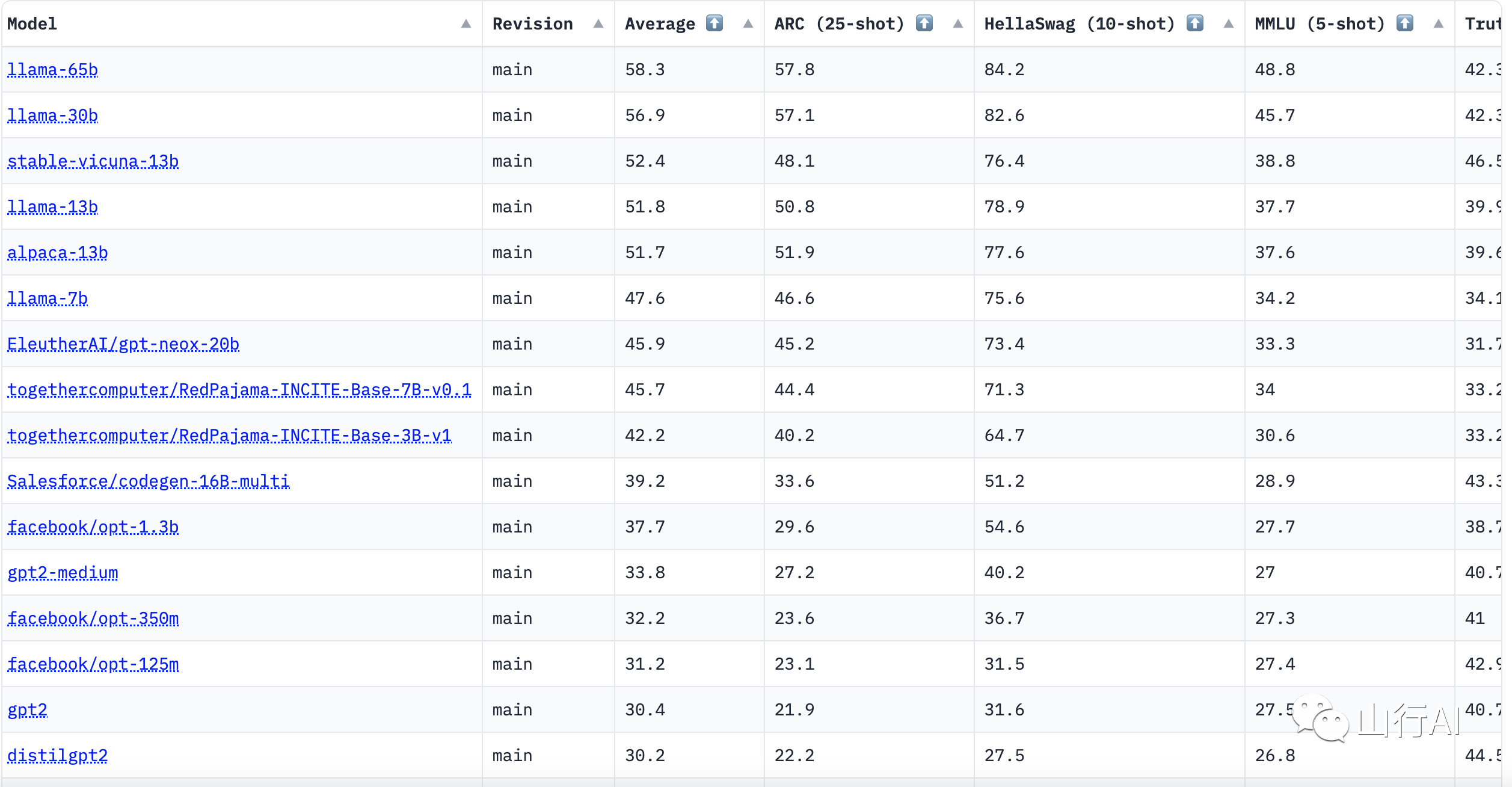
Open LLM Leaderboard 是 Hugging Face 推出的一个开源大模型排行榜单,旨在为人工智能领域的研究者和开发者提供一个公平、可靠、可持续的评估大型语言模型性能的排名系统。该排行榜单综合了多个常识和推理类评测集上的得分,包括 ARC、HellaSwag、MMLU 和 TruthfulQA 等,以帮助用户了解不同模型的性能和潜力。
Open LLM Leaderboard 的实现方式类似于 Elo 评级方法,通过对模型在多个任务上的表现进行评估,来确定它们的实力水平。该系统采用 EleutherAI 实验室创建的评估工具 Eleuther AI LM Evaluation Harness,在 Hugging Face 的计算集群上进行评估。
值得注意的是,Open LLM Leaderboard 并不局限于特定规模或领域的模型,可以适用于各种规模和领域的机器学习模型评估。通过这个公开、透明的评估平台,研究者和开发者可以实时跟踪和分析评估结果,从而更准确地了解模型的性能,优化模型,提高模型的实力水平。
相关导航






暂无评论...
开放猫AI导航站收集了包括AI写作工具、AI绘图工具、AI视频工具、AI模型工具、AI指令工具等国内外上百个最新的AIGC网站,旨在帮助大家更好的获取、了解、使用国内外好玩的AIGC工具。网址收录请联系微信:openmao23

