










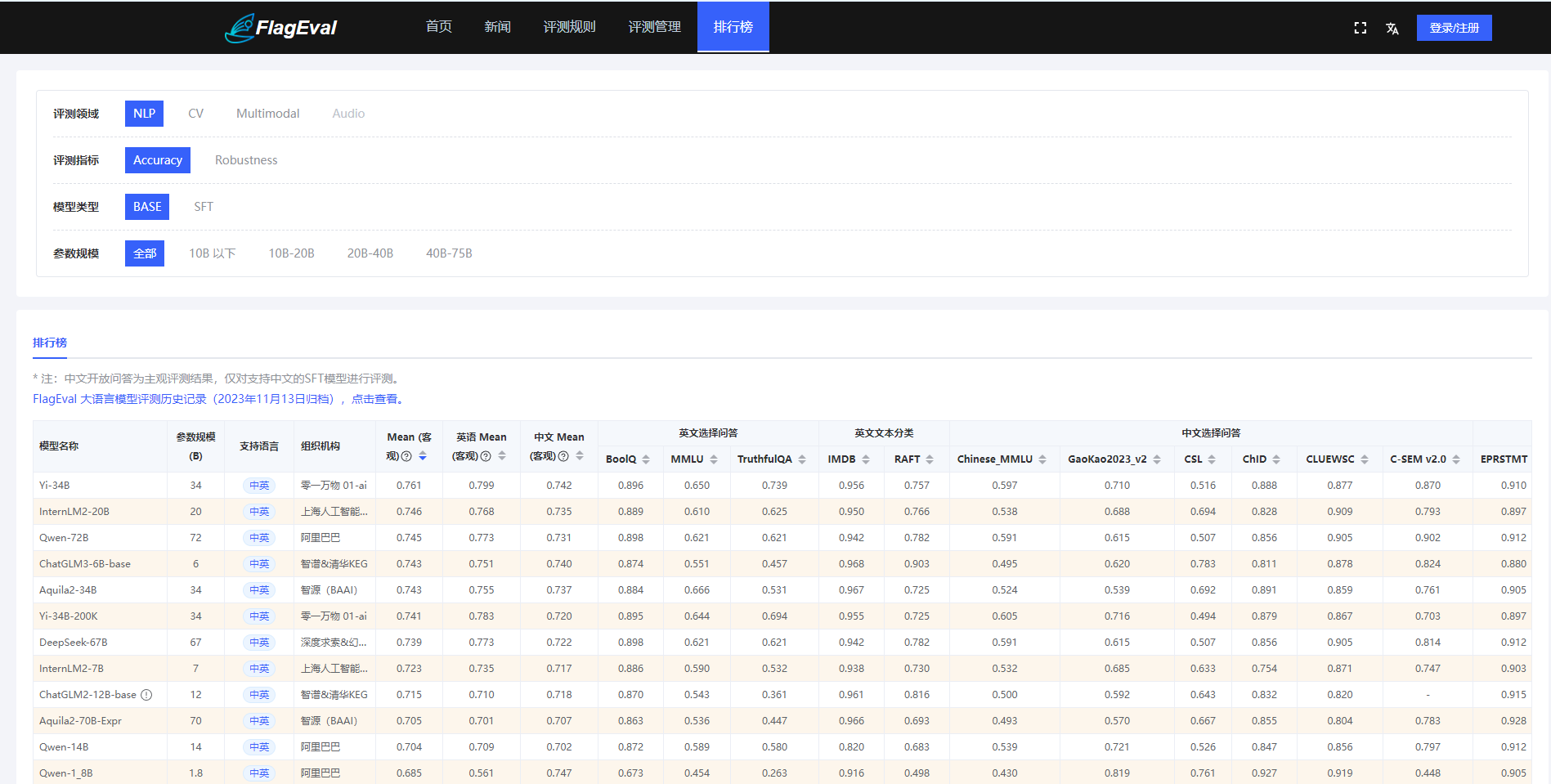
FlagEval 是智源研究院推出的大模型评测平台,名为“天秤”。该评测平台旨在建立科学、公正、开放的评测基准、方法和工具集,协助研究人员全方位评估基础模型及训练算法的性能。FlagEval 天秤大模型评测体系建立了能力-任务-指标”三维评测框架,目前涵盖了 22 个主观和客观评测集,84433 道题目,细粒度刻画大模型的认知能力。该评测平台基于 Elo 评级方法,将机器学习模型的评估过程分为训练和评估两个阶段,通过对模型进行多种不同的评估任务,全面评估模型的性能和潜力。此外,FlagEval 提供了一个公开、透明的评估平台,方便研究者和开发者实时跟踪和分析评估结果,从而更准确地了解模型的性能,优化模型,提高模型的实力水平。
FlagEval 天秤大模型评测平台具有以下特点和主要功能:
- 科学评测框架:FlagEval 建立了“能力-任务-指标”三维评测框架,从多个维度全面评估大模型的认知能力。通过这种科学的评测方法,研究人员和开发者可以更加准确地了解模型的性能和潜力。
- 公正评测方法:FlagEval 采用 Elo 评级方法进行模型评估,将评估过程分为训练和评估两个阶段。这种方法可以确保评估结果更加公正、客观,有利于研究者和开发者优化模型性能。
- 开放评测平台:FlagEval 提供了一个公开、透明的评估平台,方便研究者和开发者实时跟踪和分析评估结果。这种开放性有助于鼓励更多的研究人员和开发者参与到模型的评估和改进过程中,共同推动大模型技术的发展。
- 海量评测数据:FlagEval 评测体系涵盖了 22 个主观和客观评测集,84433 道题目,可以全面、细致地刻画大模型的认知能力。这为研究者和开发者提供了丰富的数据资源,以便他们更好地了解模型的性能和潜力。
- 持续更新:FlagEval 评测平台会随着新的评测集和任务的加入而不断更新,保持与行业发展同步。这有助于研究者和开发者始终掌握最新的评测方法和工具,从而提高模型的性能水平。
总之,FlagEval 天秤大模型评测平台通过提供科学、公正、开放的评测方法和工具,帮助研究者和开发者全面评估大模型及训练算法的性能,从而推动大模型技术的发展。
相关导航






暂无评论...
开放猫AI导航站收集了包括AI写作工具、AI绘图工具、AI视频工具、AI模型工具、AI指令工具等国内外上百个最新的AIGC网站,旨在帮助大家更好的获取、了解、使用国内外好玩的AIGC工具。网址收录请联系微信:openmao23

