“GPT-5还没来,开源先行一步。”
8月6日凌晨,OpenAI突然“整了个大的”——不是我们苦等的GPT-5,但却是六年来首次开源语言模型,而且一下子就是两款!

名字也不藏着掖着,就叫gpt-oss-120b和gpt-oss-20b,代表“Open Source Series”。这意味着,从GPT-2至今6年,OpenAI终于再次释放权重,并对全世界开发者说了一句:
“拿去用,免费,商用也行!”
而且,就连老黄家的H100、苏妈家的锐龙芯片也卷进来了……
01|开源“王炸”:能本地跑、能商用,还性能不俗
我们先来看看这两款模型的硬核规格:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🔧 **MoE(专家混合架构)**能在保持超大规模的同时,显著减少推理所需资源。比如120b实际只激活了5.1B参数,照样打得有模有样。
更香的是:Apache 2.0开源协议,意味着你不需要授权、不用付费,想商用就商用,拿来就能上!
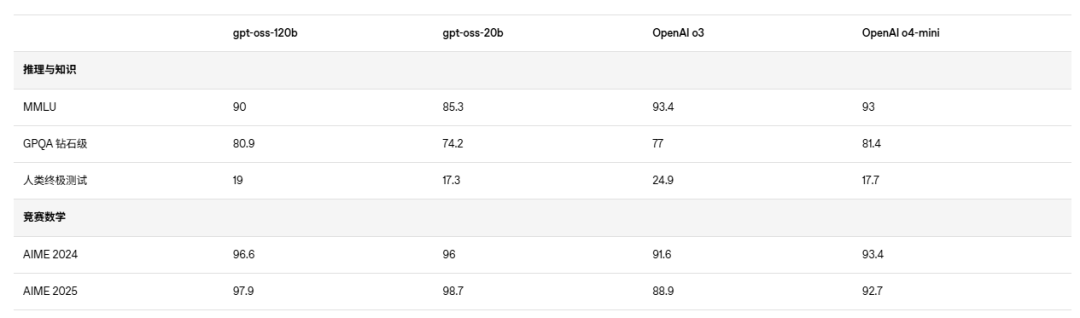
从性能角度来看,gpt-oss已经达到了开源模型里推理性能的第一梯队,但在代码生成和复杂推理任务中仍略逊于闭源模型(如GPT-o3和o4-mini)。
02|实测:在MacBook Pro上跑120b,竟然这么丝滑?
发布一小时后,OpenAI立马在X平台放出了一段实测演示视频:
- 主角是OpenAI开发者体验团队的Dom和Zhaohan
- 场景是在一台120G内存的MacBook Pro上,借助 Ollama 工具,在本地加载运行gpt-oss-120b(注意:连接了两块H100)
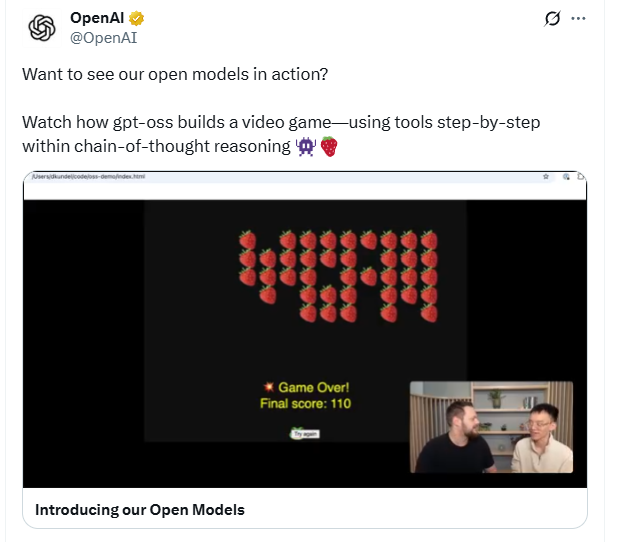
他们现场演示了两件事:
- 问旧金山天气,模型调用了本地Browser Tool,顺利返回正确答案;
- 两个巨型数字相乘,模型自动调用Python工具进行分步计算,虽然中途出错了一次,但最终结果无误。
平均生成速度:40-50 tokens/s,表现相当顺畅。
视频链接:https://x.com/i/status/1952804171419373650
一句话总结:这不仅能跑,而且还能跑得起,跑得快。
03|评测打榜:开源界的“性能天花板”?
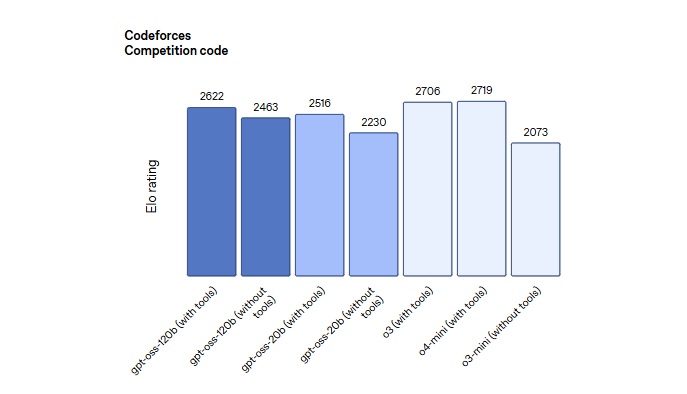
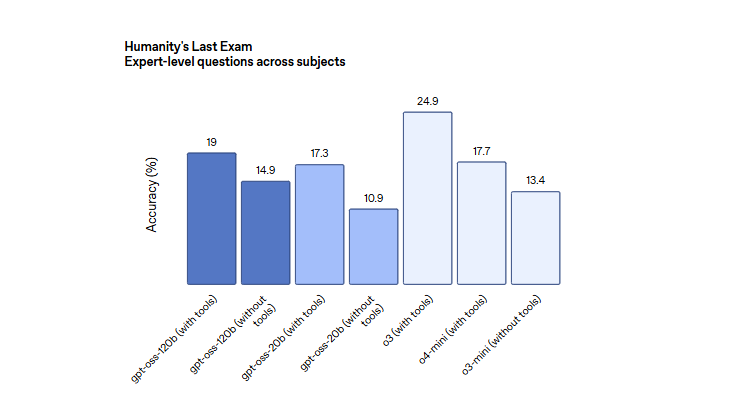
OpenAI技术博客也同步放出了一大波评测数据。
- 在编程能力、竞赛数学、医学问答、链式推理、工具使用等方面,
- gpt-oss-120b的整体表现甚至超过o4-mini,基本稳坐开源模型性能的第一梯队;
- 而“小号”gpt-oss-20b也超越了o3-mini,在健康问答、数学任务上表现抢眼。
04|模型架构:一切为了高效推理与部署
gpt-oss使用的依然是Transformer骨架,但在效率上可谓“卷出花”:
- 专家混合(MoE)结构:每次推理只激活一小部分参数;
- 交替密集 + 稀疏注意力:既能捕捉长依赖,又节省计算资源;
- 分组多查询注意力(Grouped MQA):组大小为8,提升并发性能;
- 支持128k超长上下文,对话上下文拉满;
- RoPE旋转位置编码:处理长文本更稳定。
在预训练上,数据以英语为主,重点强化STEM知识、编程和通识问答能力。
而使用的分词器“o200k_harmony”也是和GPT-4o同款,OpenAI这次一并开源。

05|后训练:对齐o4-mini同级标准,支持推理强度调节
训练完的模型还需要“打磨”,这一步被称作后训练(post-training)。
OpenAI对这两个模型进行了:
- 监督微调(SFT);
- 高算力强化学习(RLHF);
- 工具调用 + CoT链式思维训练。
更重要的是,开发者可以通过一句系统提示词,自由调节推理强度(低、中、高),在性能与响应速度之间实现灵活权衡。
06|为啥开源?Altman的回答很明确
OpenAI在技术博客末尾解释了开源动机:
- 能力够了:gpt-oss 系列在安全性和推理能力上都已成熟;
- 丰富生态:为开发者提供更多工具选项,补充托管模型;
- 加速创新:鼓励前沿研究和应用多样性;
- 降低门槛:让中小团队、发展中国家也能负担得起;
- 推动AI民主化:构建健康的开源生态系统,让AI真正“普惠全球”。
“这是朝着高能力开源模型迈出的重要一步。”
07|但网友最关心的,还是那句灵魂拷问:
GPT-5呢???
虽然这次不是GPT-5,但gpt-oss系列的开源,无疑是在告诉全世界一个信号:
“下一代AI,不一定非要托管在云端,你也可以在本地掌控。”
也许这正是OpenAI在通往AGI之路上的重要转弯点。

相关文章

