1.什么是 AI Agent
AI Agent 是一种软件系统,运用人工智能技术来达成特定目标、执行任务。它不仅具备推理、规划、记忆等能力,还拥有一定的自主性,能够做出决策、持续学习并适应环境。Agent 可以同时处理文本、语音、图像、视频、音频和代码等多种类型的信息,具备强大的对话、理解和操作能力。
Agent 与工作流(Workflow)的本质差异:
传统的工作流通过预设流程完成任务,逻辑是静态的、固定的;而 AI Agent 在运行时动态确定策略、调用工具,并在执行中不断反思与调整,表现出更高的灵活性和智能水平。
深入理解 Agent 的高级能力,如自主性与复杂任务决策,是将其与普通聊天机器人或基础助手区别开的关键。这也正是为什么 Agent 系统需要更复杂、精细的底层基础设施来支撑。
Agent 所依赖的基础设施,应涵盖其整个生命周期,包括研发、部署、运行与迭代等所有阶段。
2.AI Agent 的核心功能模块
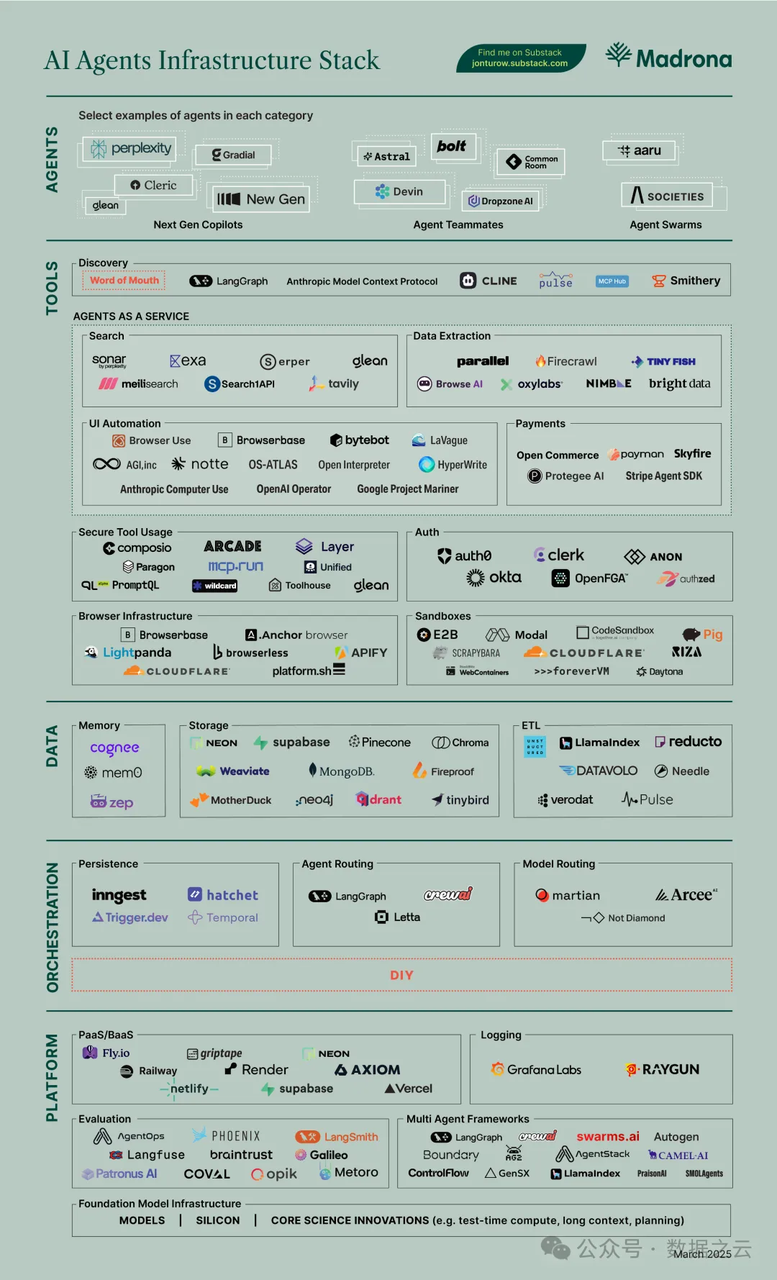
AI Agent 的强大来源于多个核心组件的协同工作,这些模块共同赋予其感知、思考、判断和行动的能力。
2.1 核心“大脑”:LLM、推理与规划模块
Agent 的智能核心是以大型语言模型(LLM)为中心的“大脑”,结合推理机制和任务规划单元。
- LLM 模型:LLM 是智能行为的核心,负责语言生成、逻辑推理和任务执行等关键能力。它根据输入做出推断,并生成合理的输出结果。通过定制化提示词、角色模板、领域知识等方式,可增强其在特定任务中的表现。
- 规划模块:该模块负责理解复杂任务结构,制定多步骤计划,将复杂问题拆解为可控的执行单元。常见方法包括 Chain of Thought(CoT)、Tree of Thought(ToT)、ReAct 等,这些策略使 Agent 能够面对模糊问题时进行推演、调整路径并应对不确定性。
2.2 感知与执行模块:与外部世界互动
Agent 要实现“行动力”,就必须感知环境并采取相应动作。
- 感知模块:将环境信息提取出来,并以合适形式送达 LLM。该模块通常借助语义搜索、NL2SQL 等技术,将 LLM 的“认知需求”转化为具体的数据获取行为。
- 执行模块:该部分负责将 Agent 的决策落实为具体动作,例如调用 API、执行脚本、生成代码,或通过机器人执行物理行为。
需要注意的是,推理只是“脑力”,感知模块的准确性直接影响 LLM 的判断质量。
2.3 Memory:上下文保持与持续学习
Memory 模块让原本“无记忆”的 LLM 具备了回忆和学习能力,使其能保持连续性、理解用户习惯并适应环境变化。
- 短期记忆(STM):基于上下文窗口维持会话连续性,但易受窗口长度限制。为避免信息冗余和幻觉,短期记忆通常通过总结提炼关键信息,而不是简单保留全部历史。
- 长期记忆(LTM):通过向量数据库或知识图谱等方式进行持久化信息存储,让 Agent 从过去经验中获得洞察。其子类型包括:
- 情景记忆:记录交互事件及结果。
- 语义记忆:保存事实与定义。
- 程序记忆:学习到的技能与操作规则。
- 检索增强生成(RAG):让 LLM 从 LTM 中动态提取知识。
- 分层记忆结构:结合短期、长期和工作记忆,以提升响应准确性。
2.4 工具调用能力:打破能力边界
LLM 模型固有的能力受限于训练数据,而工具系统则让 Agent 拓展至实时场景与外部系统,显著增强其实用性。
- 工具交互协议:MCP、A2A(Agent 间交互协议)。
- 浏览器工具:如 Browserbase、Lightpanda,让 Agent 能浏览网页并进行交互。
- 工具发现机制:帮助 Agent 在海量 MCP 工具中快速识别适合自身任务的组件。
- 沙箱环境:为工具提供隔离执行的安全环境,如 E2B 平台。
- 服务类工具:
- 搜索 API(如 Tavily)
- 数据爬取工具(如 Firecrawl)
- UI 自动化、支付服务等
工具的加入将 LLM 从被动响应者升级为能完成真实任务的主动智能体。
2.5 控制器与路由器:调度多工具多任务
随着 Agent 系统复杂度提升,需要一个智能控制器来动态决定何时使用何种工具、调用哪个子任务,完成任务调度与流程编排。它协调推理、记忆、工具调用等多个模块,使 Agent 能根据实时环境智能响应。
值得强调的是,Agent 的各功能模块不是孤立的拼图,而是相互依赖、彼此联动的生态系统。一处短板(如缺失记忆或工具能力)都会影响整体智能水平。因此,Agent 基础设施设计应注重模块之间的协同与整合能力。
3.Agent 的运维基础设施
构建一个可落地、能投入生产环境的 Agent 系统,除了感知、推理、执行等“智能组件”,还必须具备强大的工程与运维支撑能力。这部分基础设施,决定了 Agent 能否规模化部署、稳定运行与高效迭代。
3.1 Prompt 管理与版本控制
在 Agent 系统中,Prompt 不再是临时测试代码,而是构成核心逻辑的一部分,承担“控制程序”的角色。因此,Prompt 需要具备以下运维能力:
- 结构化存储与版本追踪:每个 Prompt 的变动都应有版本号和变更记录,方便回溯和回滚。
- 可视化编辑工具:支持结构化 Prompt 编辑、模块化管理与调试。
- 运行上下文注入:Prompt 不应写死变量,而是根据用户输入与环境上下文动态填充。
- 效果评估与 A/B 测试:配合自动化评估系统对不同 Prompt 版本效果进行对比,选出最优策略。
Prompt 的管理方式越接近传统软件工程,系统的可维护性与可控性就越强。
3.2 日志与可观测性系统
Agent 系统是黑盒中的黑盒 —— LLM 本身就不透明,加上动态调用工具、实时记忆更新,更使得故障诊断变得复杂。
因此,一个完善的日志与监控系统是 Agent 系统可运行、可维护的前提。
- 多级日志追踪:包括 Prompt 输入输出、模型中间响应、工具调用细节、记忆读写记录等。
- 行为链路追溯:通过上下文链路(如 Trace ID)将一次任务过程中的所有动作串联起来。
- 异常监控与报警机制:识别模型幻觉、响应异常、调用失败等问题,并自动告警。
- 可视化控制台:提供交互式调试界面,便于排查问题与优化策略。
该系统的设计理念,应对标微服务架构中的“可观测性三件套”:日志、指标、追踪。
3.3 安全机制与权限控制
AI Agent 在真实场景中,可能具备极高权限 —— 它不仅能调 API、发邮件,甚至能操作账户、做出决策。
因此,安全机制必须前置介入,从设计层保障系统不被滥用或泄露信息。
- 权限分级机制:对工具调用设定白名单机制与权限边界,防止未授权行为。
- 敏感信息过滤:避免 Prompt 注入、数据泄露、系统越权等攻击路径。
- 行为审计:对 Agent 的所有操作进行审计记录,确保可追责。
Agent 安全是全系统安全中的薄弱点和新挑战,需格外重视。
3.4 评估与持续迭代体系
Agent 的进化,需要系统化评估体系提供反馈闭环,否则只能“拍脑袋调优”。
Agent 的评估系统应具备以下能力:
- 任务级评估(Task-Level Evaluation):围绕完整任务的成功率、正确性、效率等指标进行打分。
- 细粒度指标分析:例如思维链质量、工具使用是否合理、记忆引用是否准确等。
- 自动化测试与基准集:构建高质量 benchmark 数据集(如 AgentEval、GAIA),并自动运行测试流程。
- 人机对比分析:将 Agent 表现与真实用户或专家行为对比,识别差距。
没有评估体系的 Agent,终究只能停留在实验室 Demo。
4.构建 AI Agent 的工程范式
一个面向真实世界任务的 AI Agent,必须具备模型+感知+工具+记忆+调度+运维等全链路能力。相比传统 AI 应用,Agent 的工程复杂度更高,对开发者提出了全新挑战。
因此,我们需要重新审视 Agent 系统的构建方法,逐步走向标准化、模块化、平台化。
Agent 架构的工程分层:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在这个体系中,Agent 不只是 LLM 的一次调用,而是一个由多个异构模块协作完成任务的“智能系统”。
5.写在最后:Agent 基础设施的未来展望
从某种角度看,Agent 正在成为通往通用人工智能(AGI)的中间形态 —— 它以可组合、可编排的方式扩展了 LLM 的能力边界,使其从语言生成器,跃迁为能够“理解世界、行动执行”的智能体。
Agent 的发展正催生一个庞大的基础设施生态:
- 从 PromptOps 到 MemoryOps,每一层都对应传统软件工程中的 DevOps 模型。
- 类似于“容器 + CI/CD + K8s”的软件部署体系,Agent 世界也将出现标准化的运行栈。
- 我们或许正在进入 “Agent-native infra” 时代:开发、部署、监控、优化都将围绕 Agent 为中心进行再设计。
未来构建 AI 系统的范式将不再是“调用一个模型”,而是“编排多个 Agent + 模型 + 工具 + 环境”的动态系统。
谁能率先构建出完善的 Agent 基础设施平台,谁就可能成为下一代 AI 的操作系统。

相关文章

