如果哪天你看到 AI 在国际象棋上吊打人类,请别惊讶。
因为,它们已经开始互相“火拼”了——而且,比你想象的还要狠!
谷歌刚刚发起了一场前所未有的大戏:首届大模型国际象棋对抗赛正式开打!各大 AI 模型纷纷上场厮杀,OpenAI、xAI、Anthropic、月之暗面、DeepSeek 等顶级玩家全员参战,掀起了一场没有硝烟的“AI兵棋推演”。
谁最聪明?谁最容易翻车?谁是“假装会下棋”的混子?在这场智商对决中,答案初现端倪。
首轮战况出炉:Grok 4 统治级表现,强势登顶热门宝座!
这场比赛在 Kaggle 推出的新平台 Kaggle Game Arena 上举行,为期三天,规则非常硬核:所有大模型禁止调用国际象棋引擎如 Stockfish,全靠“裸脑”下棋!
首日比赛结果刚刚公布——8大模型激战四场,最终 四强诞生:
- Grok 4(xAI):4-0 击败 Gemini 2.5 Flash
- o4-mini(OpenAI):4-0 战胜 DeepSeek R1
- o3(OpenAI):4-0 横扫 Kimi k2
- Gemini 2.5 Pro(Google):4-0 擊败 Claude 4 Opus
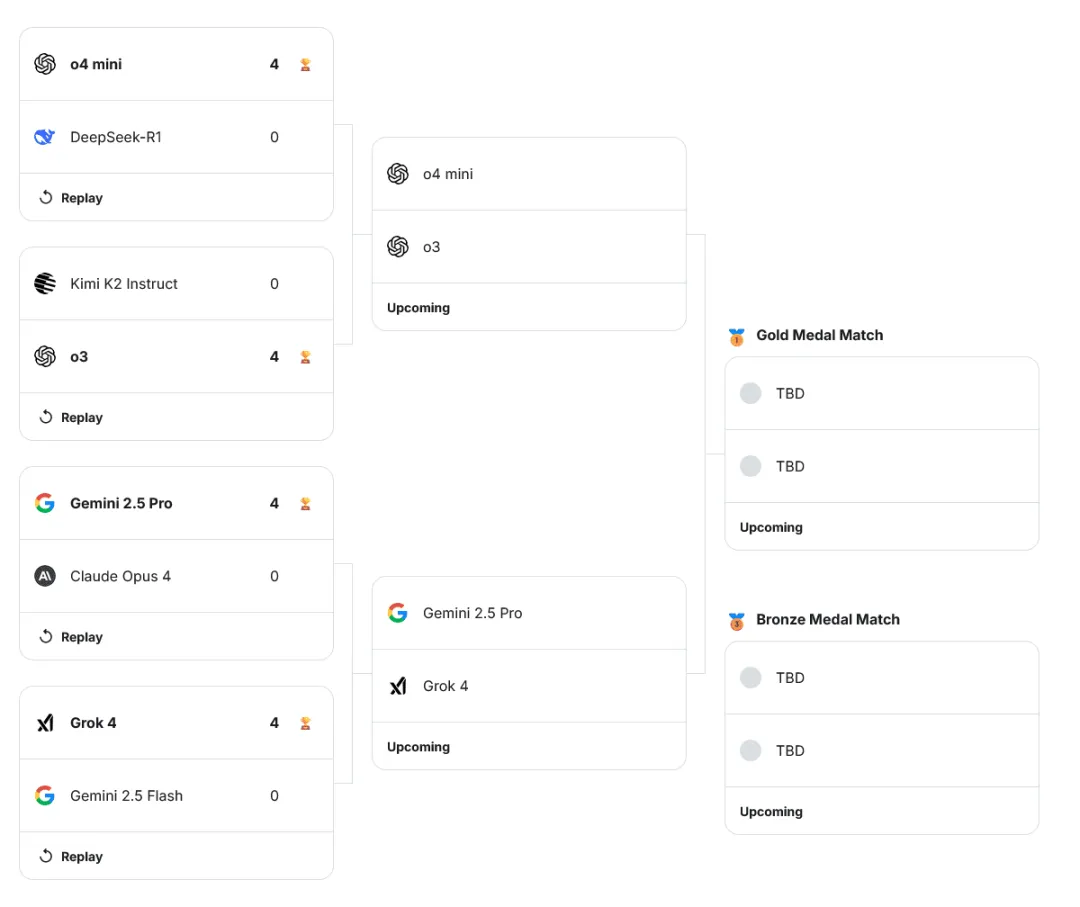
首轮全是“干净利落”的碾压局面,这也让观众惊呼:“AI 模型怎么都这么猛?!”
但细看每一场比赛的细节,就会发现——AI 的“智力水平”差距,其实挺大。
Kimi K2:连基本规则都没掌握,“非推理模型”惨遭血洗
第一场对决中,月之暗面的 Kimi k2 对阵 OpenAI 的 o3,四局完败,每局不到八步就被KO!
究其原因?Kimi k2 竟然四次都没走出合法着法,直接被判负……
值得一提的是,Kimi k2 是一个 非推理模型,打不过 o3 属于预料之中。但通过它的棋谱可以发现,它确实能按照开局理论走出几步“像样”的棋,一旦脱离套路就完全崩盘。
这也揭示了一个关键问题:部分模型缺乏“适应性”与“临场推理”能力,开局 OK,一变形就挂。

DeepSeek R1:高开低走,o4-mini“踩着失误上位”
第二场,DeepSeek R1 对阵 o4-mini,表面上看似旗鼓相当,开局几步甚至像极了人类高手对决。
但随后,就开始不断“神操作”——
- 明明走得不错,突然迷之送子
- 看似有机会,结果自己把自己坑了
最终,o4-mini 4:0 获胜,甚至还完成了两次“将军”,这在 AI 棋局中非常罕见,显示出 o4-mini 一定的全局棋盘意识。
不过,从比赛细节来看,这一战更像是 DeepSeek R1 “自爆”,而 o4-mini 稳住了基本盘。

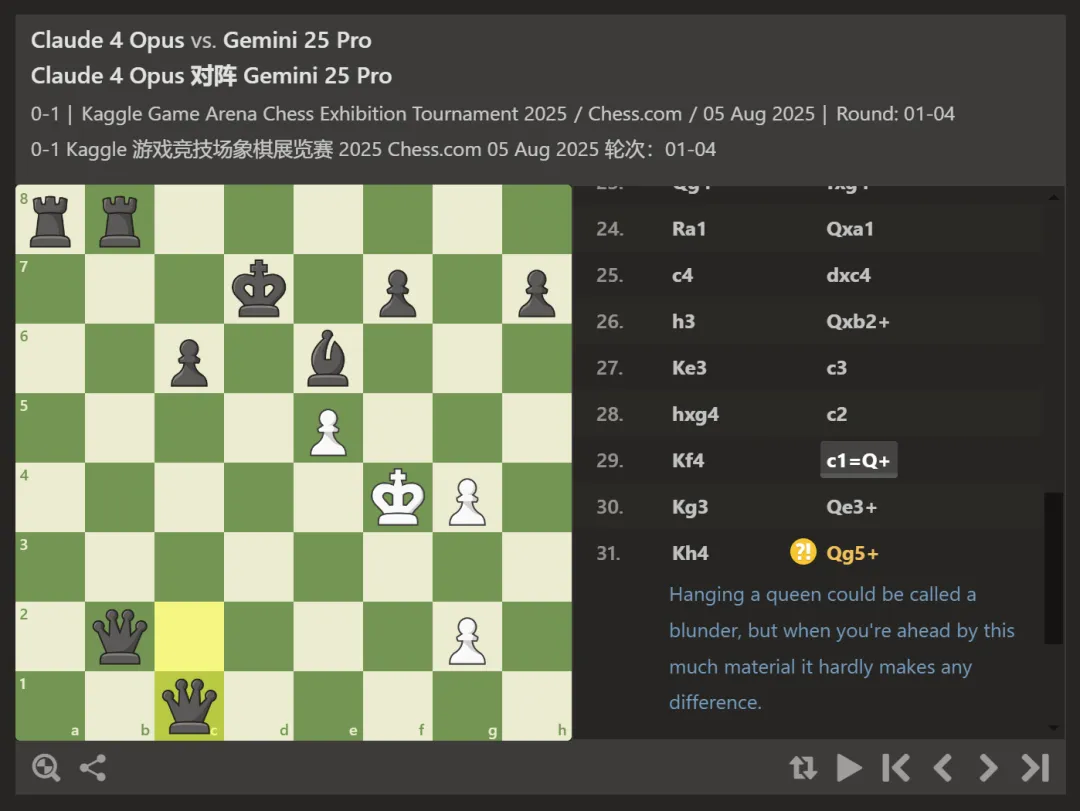
Gemini 2.5 Pro vs Claude 4 Opus:唯一“真刀真枪”的较量?
如果说前三场都是 AI 在“犯低级错误”,那这一场堪称全场最接近人类对弈的一战。
Gemini 2.5 Pro 不仅获胜方式更多是“将杀”而非对手违规,甚至还有多个回合展示出真实博弈思维:
- 第四局,Gemini 甚至出现了双后齐飞的强攻场面,但仍旧不小心送子,暴露其“粗中有细”的思维缺陷;
- 第一局的关键失误来自 Claude 4 Opus,一个 g5 送兵决策,直接让局势一泻千里。
这场比赛也说明:AI 模型的高阶对抗,还远未成熟。
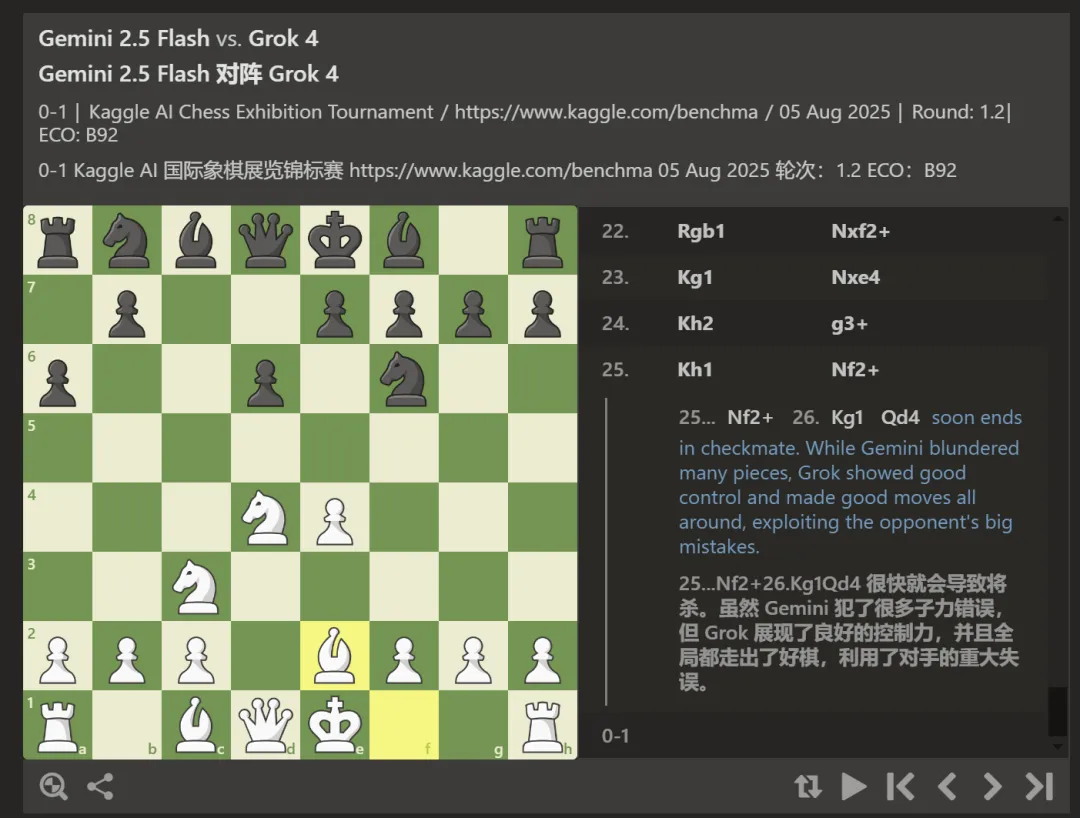
Grok 4:战术精准,几乎没有失误,技术细节拉满
今天最令人惊艳的,无疑是 马斯克家的 Grok 4!
它面对 Gemini 2.5 Flash,直接打出 4-0 的碾压比分,没有一个回合走错,没有一次送子失误,精准收割残局!
更牛的是,它展现了:
- 对棋盘全局状态的精准理解
- 对“未保护棋子”的高敏感性
- 对局面变化的快速响应能力
甚至,马斯克还在 X 平台亲自发声,再次强调他那个“老调重弹”的观点:“国际象棋太简单了。”
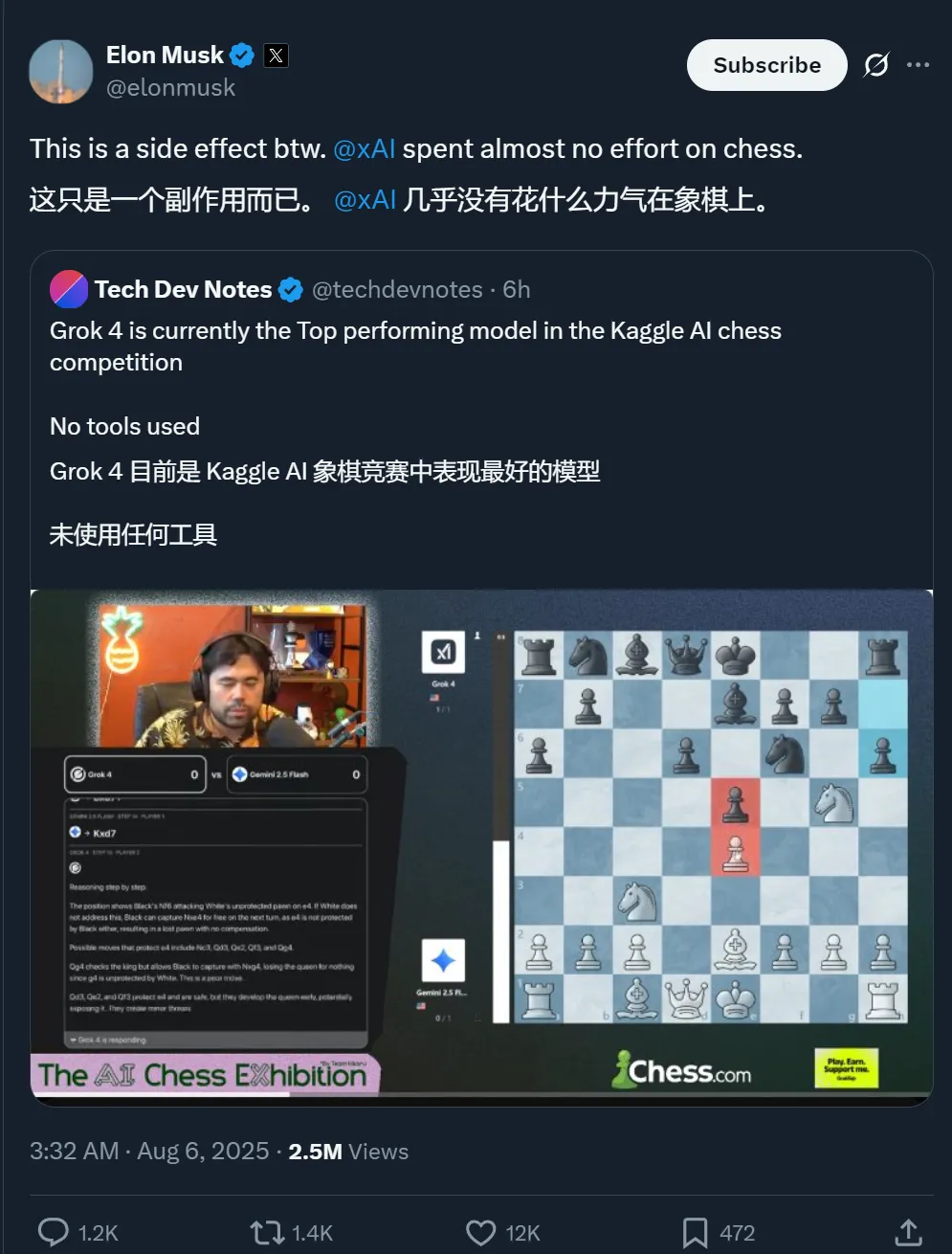
但说实话——Grok 4 的表现,确实不像在“下棋”,更像是在碾压低维生命体。
AI 象棋三大硬伤:Grok 4 正在打破它们?
这场比赛其实也暴露了大模型在国际象棋场景下的三个共性问题:
- 全局棋盘视觉化能力不强 —— 很难同时兼顾棋盘上的所有子力状态;
- 棋子互动关系理解薄弱 —— 很多模型忽略基本攻击防守链条;
- 合法着法执行失误频发 —— 连“这步棋能不能走”都搞不清楚。
而 Grok 4 的崛起,恰恰是因为它似乎正在突破这三大 AI 瓶颈,成为目前最接近“智慧下棋者”的大模型。
你心中的最强 AI 模型是谁?欢迎留言,分享你对大模型博弈的看法。

相关文章

